Reproducibility
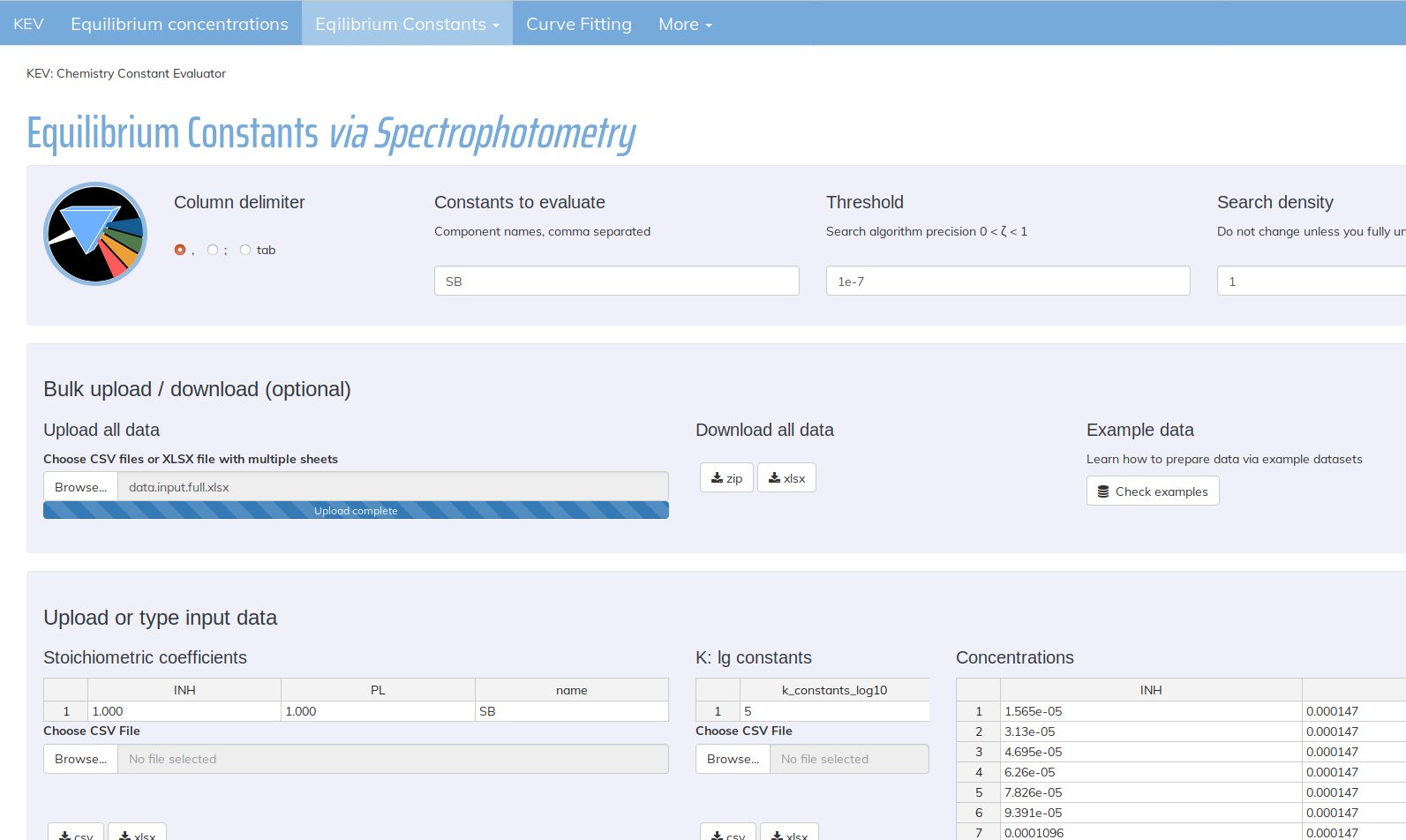
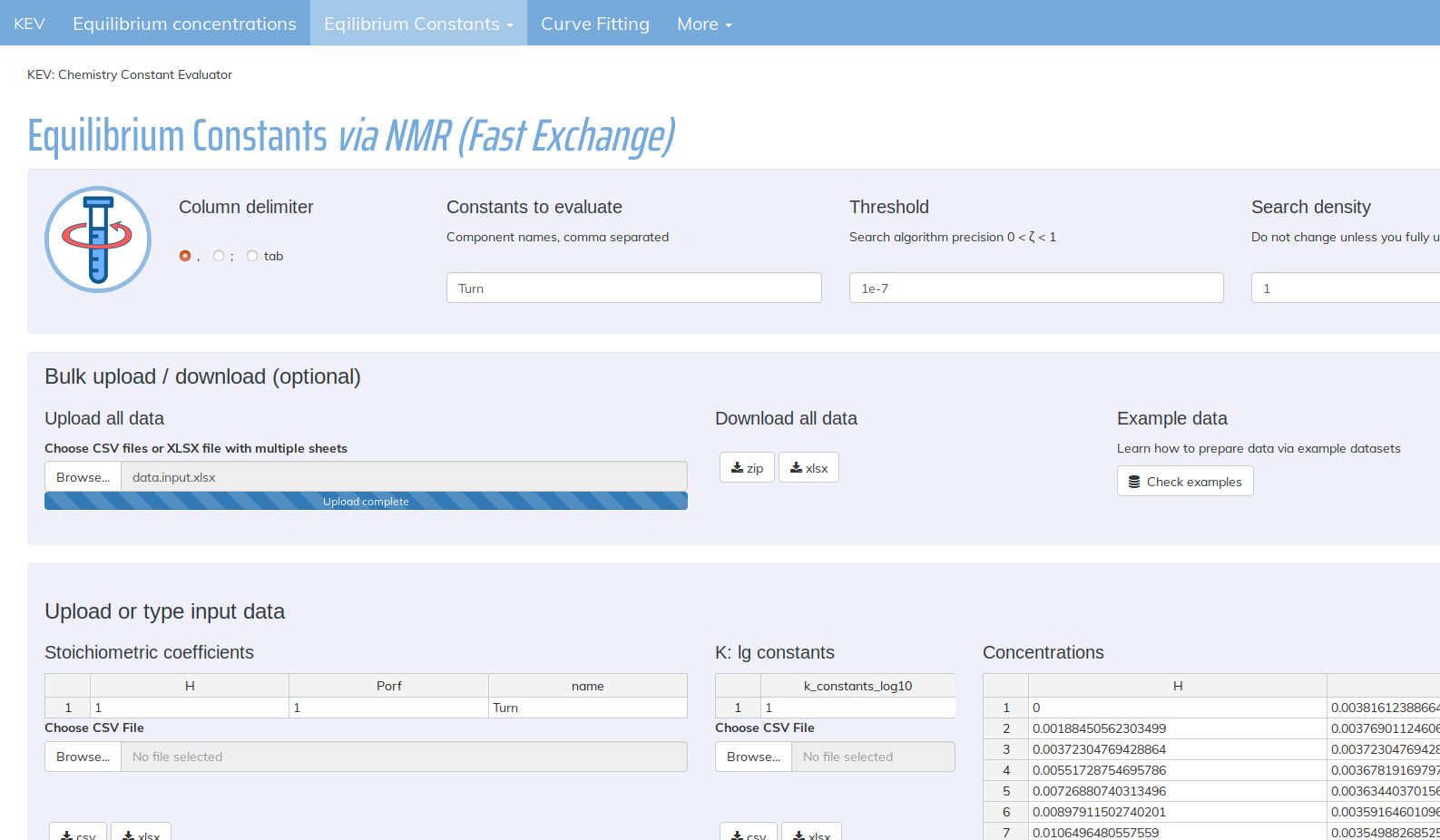
The core principle KEV is created around is the reproducibility of the (chemical) research. It uses widely accepted file formats such as csv, txt and xlsx also being easily readable and editable by humans. No special file formats, "projects" etc. are introduced, one can read, edit and save KEV input and output files with any text editor they prefer. We also use xlsx files as an option since de facto it is an office standard for the table data.
KEV provides some possibilities to edit data when loaded or input all the data manually. However, we recommend avoiding manual input since it may reduce the reproducibility of the research (unless one saves data after editing, which is also possible). All the output data could be used as the input data after rather small editing.
Verification
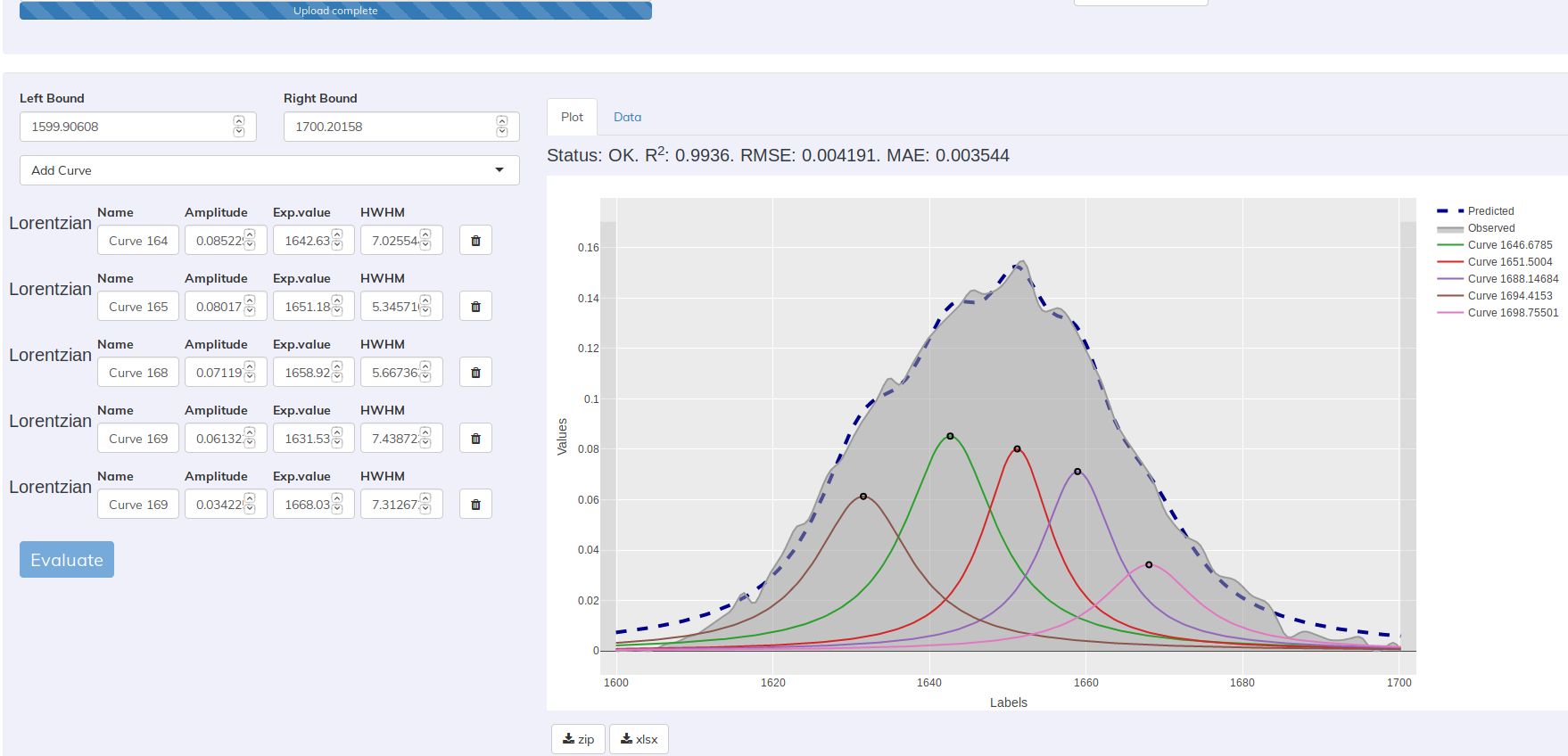
We believe it is not OK to rely on the output data of the algorithm without testing its validity. So KEV outputs contain some additional data such as correlation matrices, standard or absolute prediction errors, last reached step of the optimised function and so on. Always check them before actual use of any calculated data.
Algorithms used in KEV and other maths and statistics staff are described in the paper mentioned above.
Transparency
KEV is the only fully operational constant evaluator with the source code publicly available. The open source code and / or the independent code audit is the only way to develop truly reliable scientific software because it is the only way to be sure both about algorithms themselves and algorithm implementations as well.
Algorithm implementations deal with many extra substances from numeric precision to data input formats pure algorithms are not aware of. Each of them is the possible source of error influencing your scientific research. In fact it is much more likely to get an error from the unlucky implementation than of the maths described in the papers. We test KEV code before every update and encourage those of you who have experience in technology test it too.


 Dr. Georgiy Gamov · Chemistry and Maths ·
Dr. Georgiy Gamov · Chemistry and Maths ·  Dr. Aleksandr Meshkov · Data Science and Development ·
Dr. Aleksandr Meshkov · Data Science and Development ·